
Интеграция с AI
Мы добавили возможность поиска ответов на запрос пользователя с помощью AI моделей. Для этого мы выбрали два решения:
- RouterAI - это российский сервис, агрегирующий доступ к большому количеству моделей с оплатой по принципу Pay-as-you-go с оплатой за использованные токены. Этот сервис можно оплатить картами российских банков. Данные при этом отправляются на сервера провайдеров LLM моделей, что может не подойти для компаний имеющих строгую политику Информационной безопасности, например из государственного сектора.
- Ollama - это ПО позволяющее загрузить локально AI модели и обращаться к ним внутри сети, при этом оставляя возможность поиска в сети Интернет. Данное решение не подразумевает оплаты за использование моделей, но очень требовательно к серверным ресурсам, от 8 ядер процессора, обязательно мощное графическое ядро, от 32 GB ОЗУ и NVME хранилище.
После включения интеграции, необходимо дать права для роли "Пользователь может использовать AI анализ для заявок". В форме просмотра заявки появится кнопка для поиска на панели.
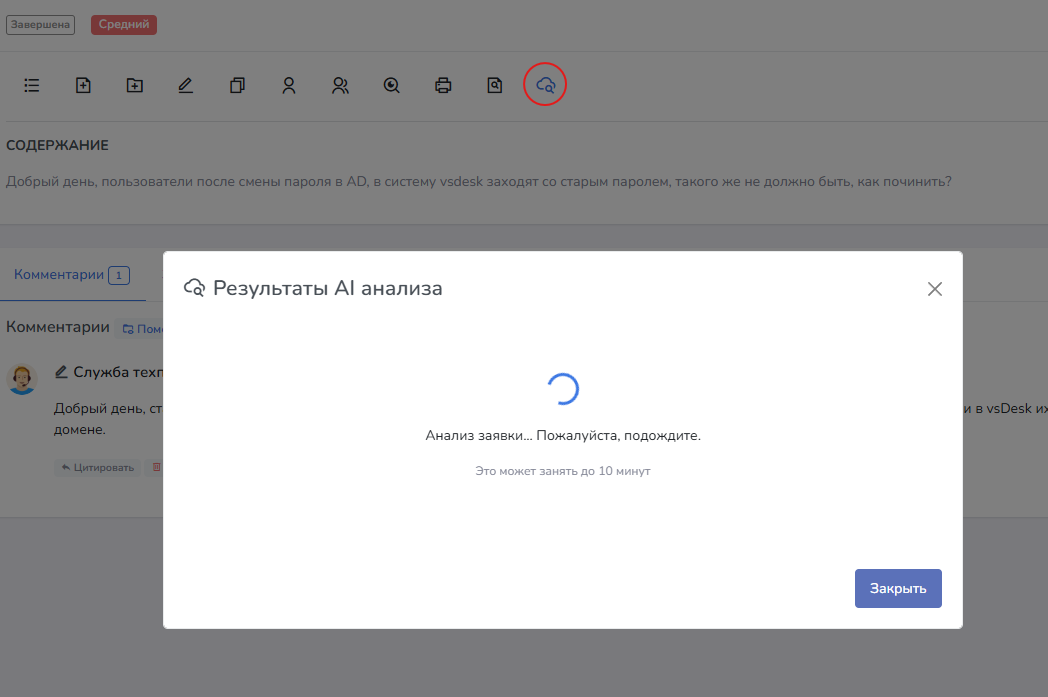
После нажатия на кнопку будет выполнен запрос к модели. Модель будет выполнять поиск релевантной информации в записях Базы знаний, в похожих заявках и комментариях, а так же в документации, указанной в виде ссылок в настройках интеграции.
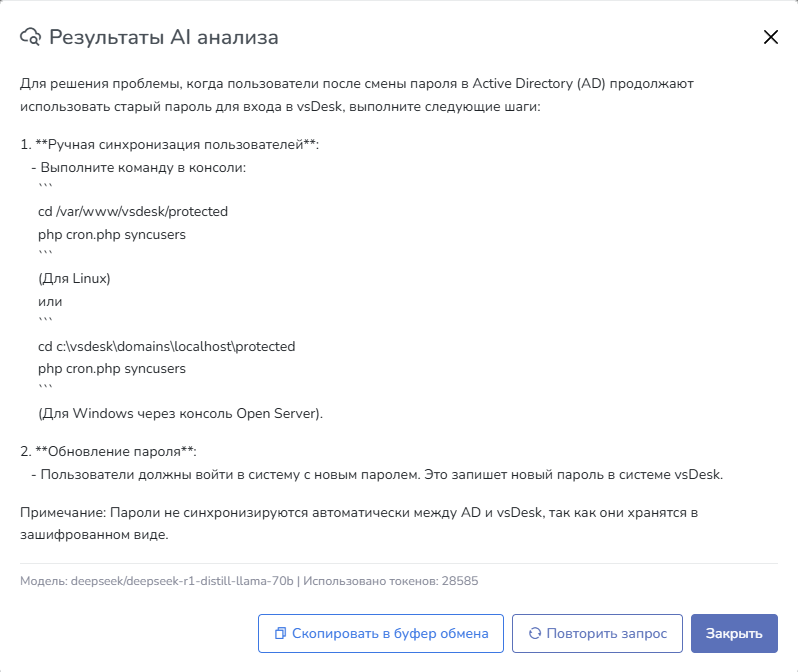
Результат полученного анализа можно скопировать для дальнейшего использования или повторить запрос, если модель дала нерелевантный ответ. Если закрыть модальное окно, то последний полученный ответ будет хранится в кэше некоторое время.
Параметры настроек интеграции
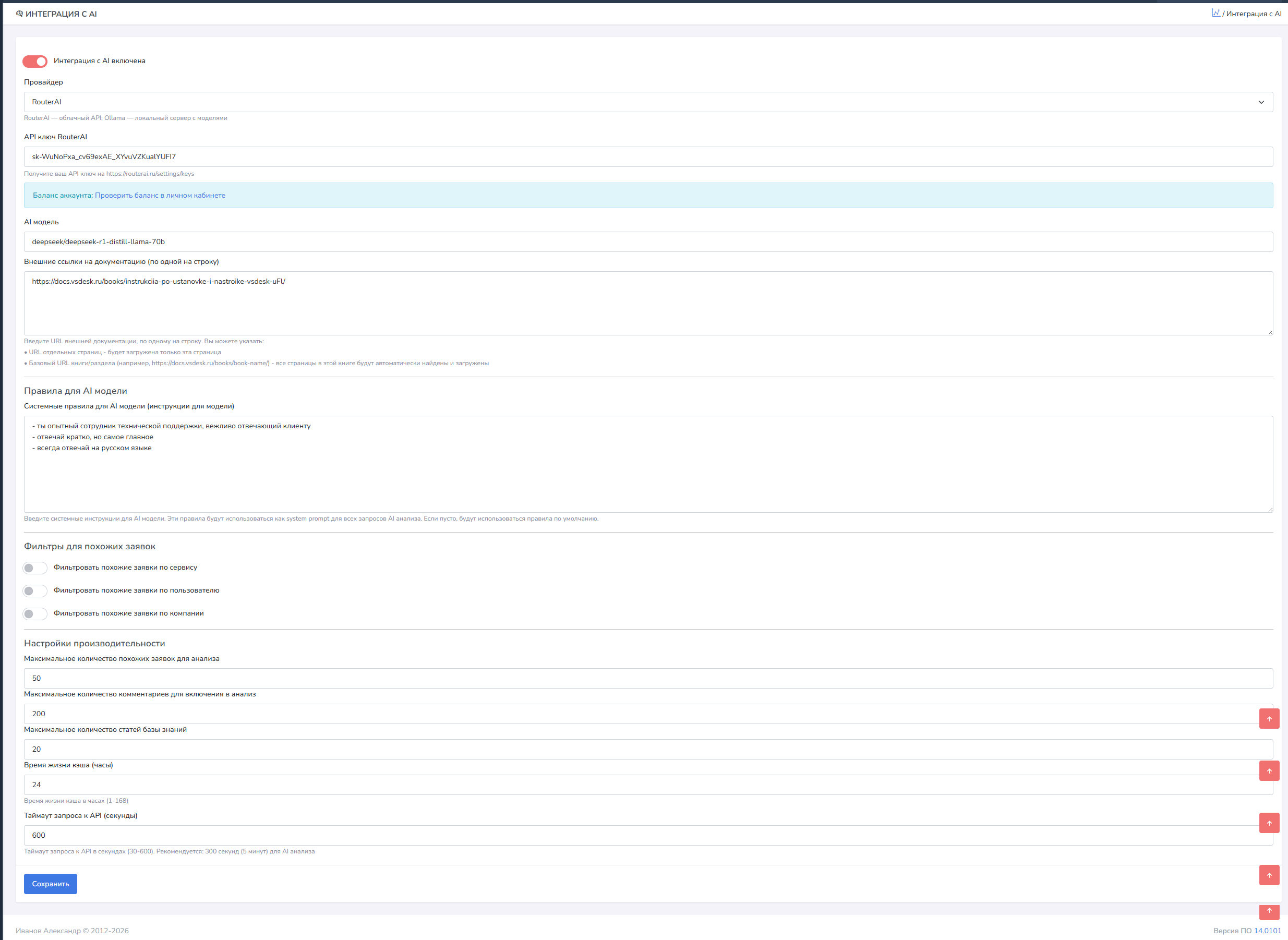
Провайдер - здесь необходимо выбрать RouterAI или Ollama какой из вариантов вы будете использовать.
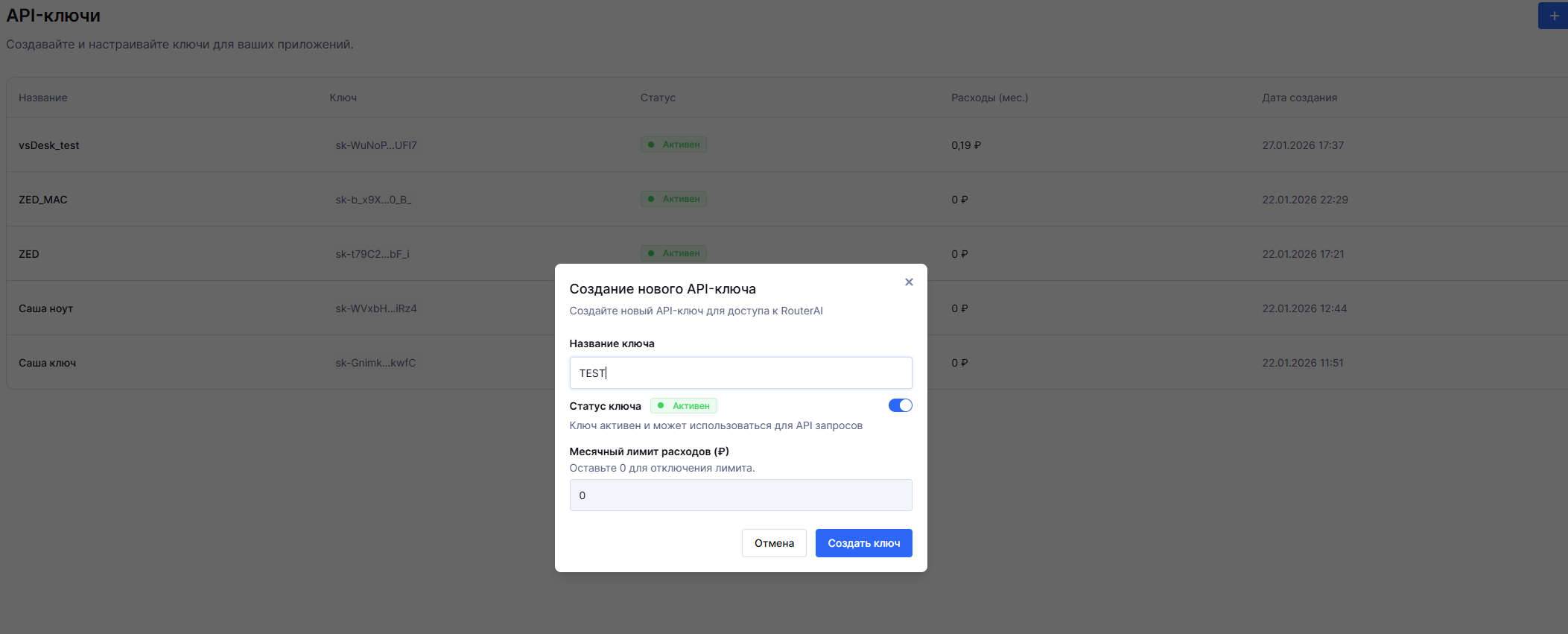
API ключ RouterAI - для использования сервиса, необходимо зарегистрироваться, получить ключ и привязать карту, пополнив баланс. После этого необходимо создать API ключ
AI модель - на сайте сервиса есть обширный список моделей которые можно использовать. но мы подобрали оптимальные по соотношению цена/качество и некоторые из моделей используем сами. Цены указаны в рублях за 1 млн токенов.
Модель | Цена входящие токены | Цена исходящие токены | Размер контекста | Изображения/Текст | Комментарий |
qwen/qwen3-vl-30b-a3b-instruct | 14 | 59 | 262к | Изображения и текст | Работает отлично, ответы точные и краткие, понимает изображения |
qwen/qwen3-vl-30b-a3b-thinking | 19 | 99 | 131к | Изображения и текст | Работает отлично, но дороже |
x-ai/grok-4.1-fast | 19 | 49 | 128к-2м | Изображения и текст | Работает хорошо, ответы точные и краткие, понимает изображения |
deepseek/deepseek-v3.2 | 24 | 37 | 164к | Текст | Выдает несколько вариантов решения, но придумывает |
|
|
|
|
|
|
nvidia/nemotron-nano-9b-v2 | 3 | 15 | 131к | Текст | Работает хорошо, ответы точные и краткие |
baidu/ernie-4.5-21b-a3b | 6 | 27 | 120к | Текст | Работает хорошо, ответы точные и краткие |
openai/gpt-5-nano | 4 | 39 | 400к | Изображения и текст | Выдает обрезанный ответ, но не всегда |
deepseek/deepseek-r1-distill-llama-70b | 2 | 10 | 131к | Текст | Работает хорошо, ответы точные и краткие, дешевая, но без изображений |
meta-llama/llama-3.2-3b-instruct | 1 | 1 | 131к | Текст | Быстрая, дешевая, не сразу выдает ответы из документации, может фантазировать |
Внешние ссылки на документацию (по одной на строку) - здесь необходимо указать ссылки на вашу документацию, в которой модель будет искать ответы на вопросы. Это могут быть внешние или внутренние ресурсы. Важно указывать ссылку на страницу, которая содержит ссылки на другие страницы, например на содержание, чтобы модель смогла обойти все ссылки.
Правила для AI модели - в данном блоке вы можете указать прямые инструкции для модели, как действовать в той или иной ситуации, как отвечать. Мы по умолчанию добавили несколько правил:
- ты опытный сотрудник технической поддержки, вежливо отвечающий клиенту
- отвечай кратко, но самое главное
- всегда отвечай на русском языке
Фильтровать похожие заявки по сервису - при включении, система будет выполнять поиск только в заявках с таким же сервисом.
Фильтровать похожие заявки по пользователю - при включении, система будет выполнять поиск только в заявках пользователя.
Фильтровать похожие заявки по компании - при включении, система будет выполнять поиск только в заявках компании пользователя.
Максимальное количество похожих заявок для анализа - количество похожих заявок, которые будут передаваться модели для анализа, мы рекомендуем 50.
Максимальное количество комментариев для включения в анализ - количество передаваемых для анализа комментариев, мы рекомендуем 200.
Максимальное количество статей базы знаний - количество передаваемых для анализа записей Базы знаний, мы рекомендуем 20.
Время жизни кэша (часы) - система кэширует данные для уменьшения количества запросов к БД. Время через которое кэш будет очищаться, мы рекомендуем 24 часа.
Таймаут запроса к API (секунды) - У каждой модели есть свое время отклика, особенно при использовании ollama, мы рекомендуем выставлять таймаут в 600 секунд (10 минут).
Параметры ollama
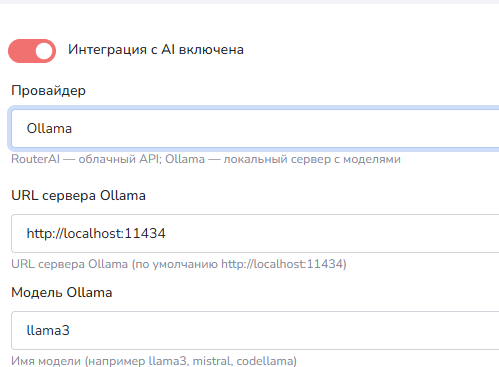
при выборе Ollama в качестве провайдера настройки будут отличаться от RouterAI
URL сервер Ollama - при запуске ollama принимает запросы по 11434 порту, вам нужно указать IP адрес развернутого приложения.
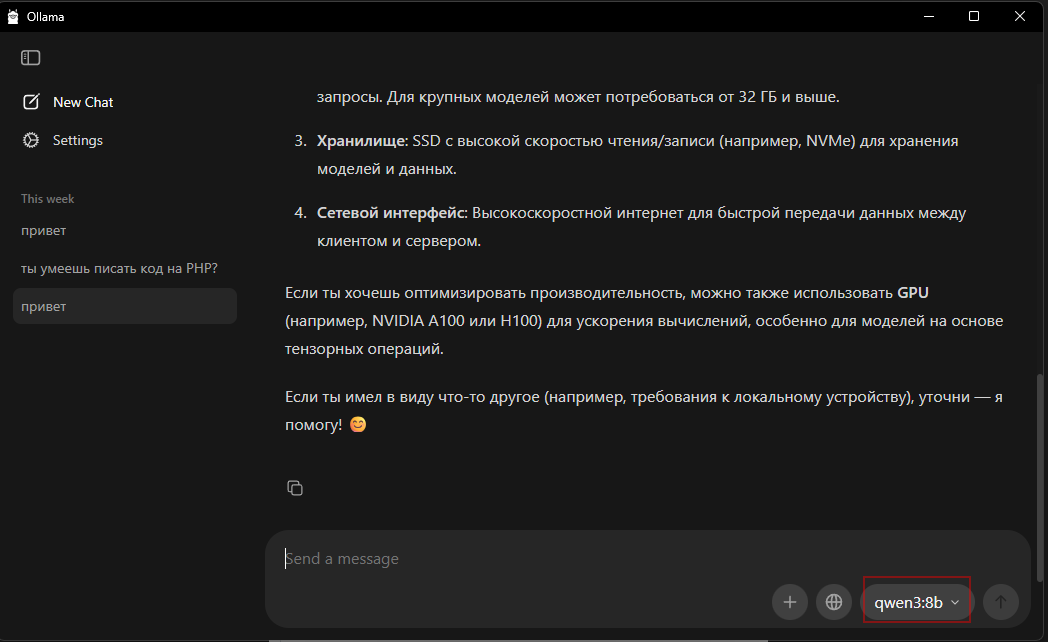
Модель Ollama - После запуска приложения вам необходимо скачать модель выбрав нужную в выделенном блоке на скриншоте и написать ей любое сообщение, после того как модель скачается, все запросы будут отправляться локально. Мы рекомендуем минималистичную и быструю модель gemma3:4b
Все остальные настройки будут одинаковы!